1. Definition
在机器学习领域, 人们总是希望使自己的模型尽可能准确地描述数据背后的真实规律. 通俗所言的「准确」, 其实就是误差小. 在领域中, 排除人为失误, 人们一般会遇到三种误差来源: 噪声(随机误差), 偏差和方差. 偏差和方差又与「欠拟合」及「过拟合」紧紧联系在一起.
对测试样本 $\boldsymbol{x}$, 令 $y_D$ 为 $\boldsymbol{x}$ 在数据集中的标记, $y$ 为 $\boldsymbol{x}$ 的真实标记, $f(\boldsymbol{x};D)$ 为训练集 $D$ 上学得模型 $f$ 在 $\boldsymbol{x}$ 上的预测输出. 以回归任务为例, 学习算法的期望预测为
假设:
我们在这里简单认为 $\boldsymbol{x}$ 属于训练集 $D$. 另外, 设有 $n$ 个训练集 $D_1,…,D_n$, 这 $n$ 个训练集都是以独立同分布方式从样本空间采样而得, 并且恰好都包含测试样本 $\boldsymbol{x}$, 该样本在这 $n$ 个训练集是的标记分别为 $y_{D_1},…,y_{D_n}$.
噪音 (随机误差)
随机误差是数据本身的噪音带来的, 这种误差是不可避免的. 一般认为随机误差服从高斯分布, 记作 $\epsilon \sim\mathcal{N}(0,\sigma_{\epsilon})$. 噪声表达了当前任务在任何学习算法所能达到的期望泛化误差的下界, 即刻画了学习问题本身的难度. 因此, 噪音可以记作
偏差 (Bias)
描述的是通过学习拟合出来的结果之期望, 与真实规律之间的差距, 即刻画了学习算法本身的拟合能力, 记作
方差 (Variance)
描述的是通过学习拟合出来的结果自身的不稳定性, 度量了同样大小的训练集的变动所导致的学习性能的变化, 即刻画了数据扰动所造成的影响, 记作
通过简单的多项式展开合并, 可对算法的期望泛化误差进行分解:
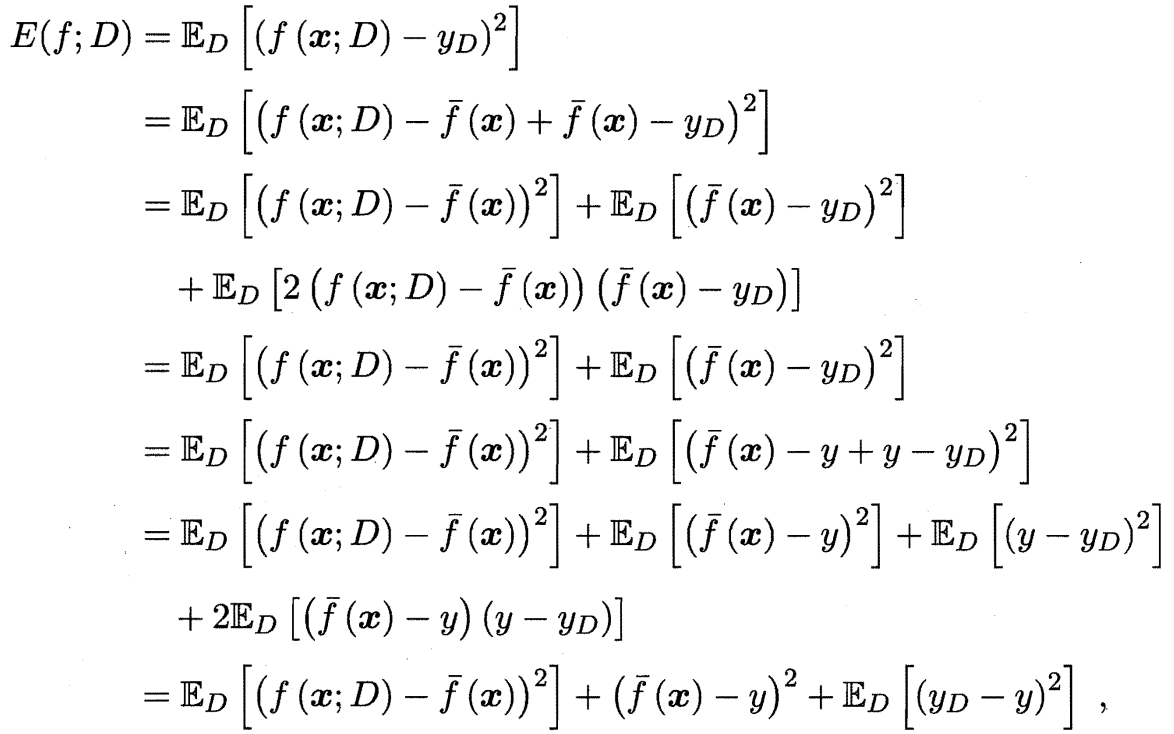
于是
也就是说, 泛化误差可以分解为偏差, 方差与噪声之和.
接下来我们看一下上诉公式是如何推导的.
==第 1 个等号:== 这是期望泛化误差的定义式, 类似地, 可直观地写为
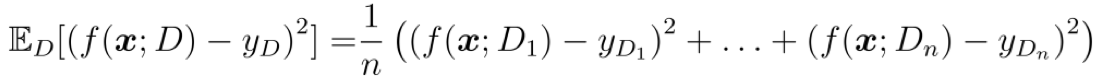
我们只能使用数据集中的标记 $y_D$ 评估学习器的泛化性能, 因为真实标记 $y$ 未知;
==第 2 个等号:== 常用的配项技巧, 减去 $\bar{f}(x)$ 再加上 $\bar{f}(x)$, 相当于没有任何变化;
==第 3 个等号:== 令 $a=f(x;D)-\bar{f}(x),b=\bar{f}(x)-y_D$, 则 $(a+b)^2=a^2+b^2+2ab$, 再结合数学期望的性质 $\mathbb{E}[X+Y]=\mathbb{E}[X]+\mathbb{E}[Y]$ 即可;
==第 4 个等号:== 只须证明第 3 个等号最后一项等于 0, 首先
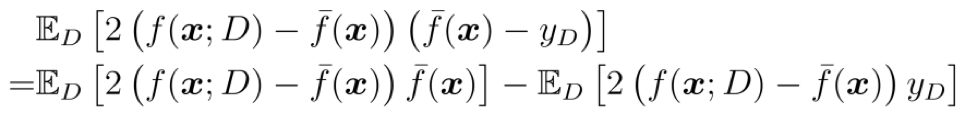
对于第一项

其中第 1 个等号就是乘开, 把式子的括号去掉; 第 2 个等号是因为期望 $\bar{f}(x)$ 为常量, 因此 $\mathbb{E}_D[·]$ 运算不起作用; 第三个等号使用了 $\bar{f}(x)$ 的定义;
对于第二项
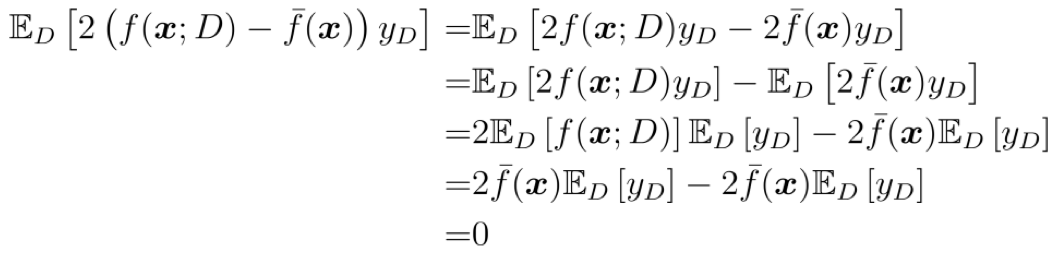
其中第 1 个等号就是乘开, 把式子的括号去掉; 第 2 个等号是根据数学期望的性质 $\mathbb{E}[X+Y]=\mathbb{E}[X]+\mathbb{E}[Y]$; 第 3 个等号中第 1 项 $\mathbb{E}_D[2f(\boldsymbol{x};D)y_D]=2\mathbb{E}_D[f(\boldsymbol{x};D)]\mathbb{E}_D[y_D]$ 是根据数学期望的性质 “当随机变量 $X$ 和 $Y$ 相互独立时, $\mathbb{E}[XY]=\mathbb{E}[X]\mathbb{E}[Y]$”; 第 3 个等号中第 2 项是因为期望 $\bar{f}(x)$ 为常量; 第 4 个等号使用了 $\bar{f}(x)$ 的定义;
综上所述: 第 3 个等号最后一项等于 0, 代入即得第 4 个等号;
==第 5 个等号:== 类似于第 2 个等号, 对第 2 项使用了配项技巧;
==第 6 个等号:== 类似于第 3 个等号, 对第 2 项使用了期望性质 $\mathbb{E}[X+Y]=\mathbb{E}[X]+\mathbb{E}[Y]$;
==第 7 个等号:== 只须证明第 6 个等号最后一项等于 0; 由于 $\bar{f}(x)$ 和 $y$ 均为常量, 因此
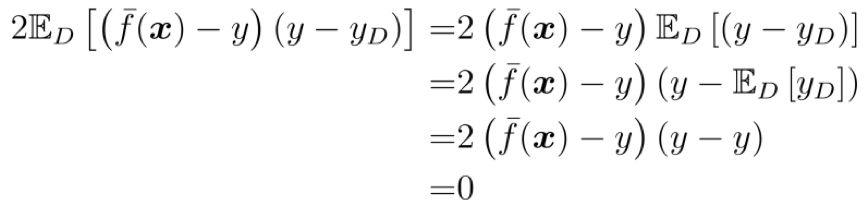
第 3 个等号使用了等式 $\mathbb{E}_D[y_D]=y$, 这是由于我们假定噪声期望为零, 即 $\mathbb{E}_D[y_D-y]=\mathbb{E}_D[y_D]-y=0$, 其中 $y$ 为 $\boldsymbol{x}$ 的真实标记, 是一个常量;
偏差-方差分解说明: 泛化性能时由学习算法的能力, 数据充分性以及学习任务本身的难度所共同决定的. 给定学习任务, 为了取得好的泛化性能, 则需偏差较小, 即能够充分拟合数据, 并且使方差较小, 即使数据扰动产生的影响小.
2. Graphic Explanation
我们看看如何用图形来表示 Bias 和 Variance:
下图将机器学习任务描述为一个「打靶」的活动: 根据相同的算法, 不同的数据集训练出的模型, 对同一个样本进行预测, 每个模型作出的预测相当于是一次打靶. 我们假设红色靶心区域是真正的值, 蓝色点为不同训练集所训练出的模型对样本的预测值, 当我们从靶心逐渐向外移动时, 预测效果逐渐变差.
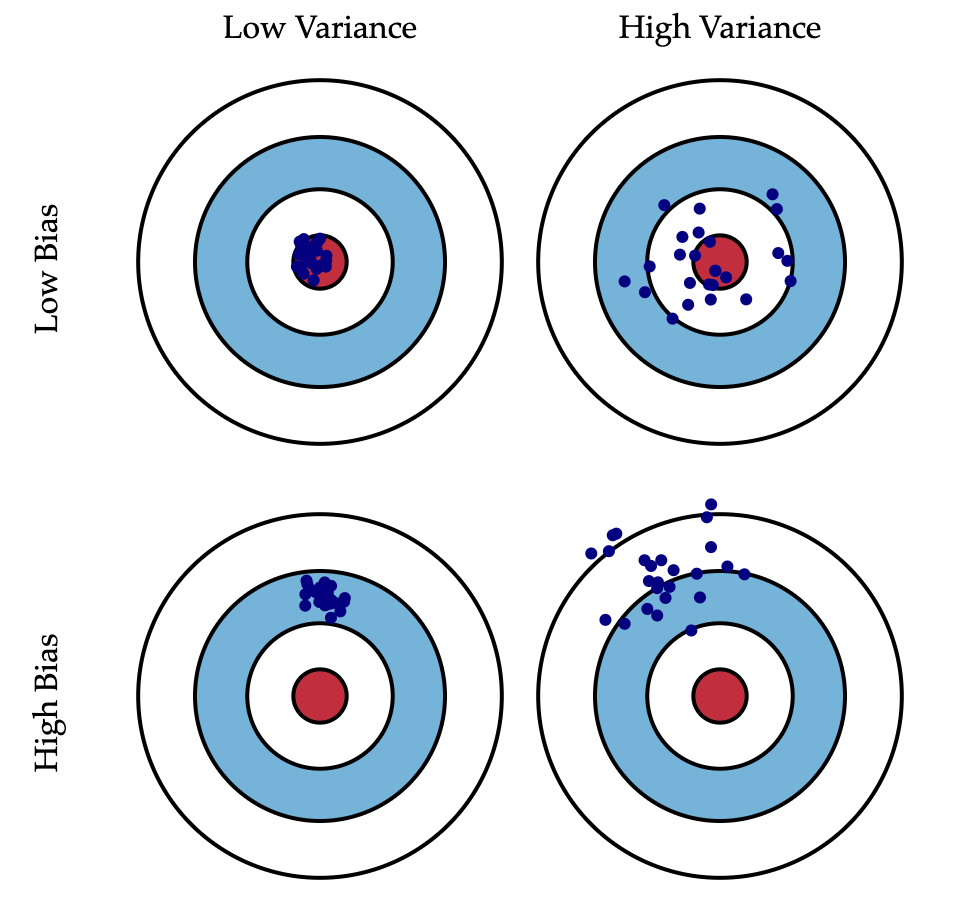
左上角的示例是理想状况: Bias 和 Variance 都非常小, 如果有无穷的训练数据, 以及完美的模型算法, 我们是有办法达成这样的情况的. 然而, 现实中的工程问题, 通常数据量都是有限的, 模型也不是完美的. 因此, 这只是一个理想状况.
右上角的示例表示: Bias 小, Variance 大. 靶纸上的落点都集中分布在红心周围, 它们的期望落在红心之内, 因此偏差较小. 另外一方面, 落点虽然集中在红心周围, 但是比较分散, 这是方差大的表现.
左下角的示例表示: Bias 大, Variance 小. 显而易见, 靶纸上的落点非常集中, 说明方差小. 但是落点集中的位置距离红心很远, 这是偏差大的体现.
右下角的示例则是最糟糕的情况: Bias 和 Variance 都非常大. 这是我们最不希望看到的结果.
3. Example
现在我们做一个模拟实验, 用于说明至此介绍的内容. 首先, 我们生成了两组 array, 分别作为训练集和验证集. 这里 $x$ 和 $y$ 是线性相关的, 而在 $y$ 上加入了随机噪声, 用以模拟真实问题的情况.
1 | import numpy as np |
现在, 我们选用最小平方误差作为损失函数, 尝试用多项式函数去拟合这些数据.
1 | prop = np.polyfit(x_train,y_train,1) |
这里, 对于 prop, 我们采用了一阶的多项式函数 (线性模型) 去拟合数据; 对于 overf, 我们采用了 15 阶的多项式函数 (多项式模型) 去拟合数据. 如此, 我们可以把拟合效果绘制成图.
1 | import matplotlib.pyplot as plt |
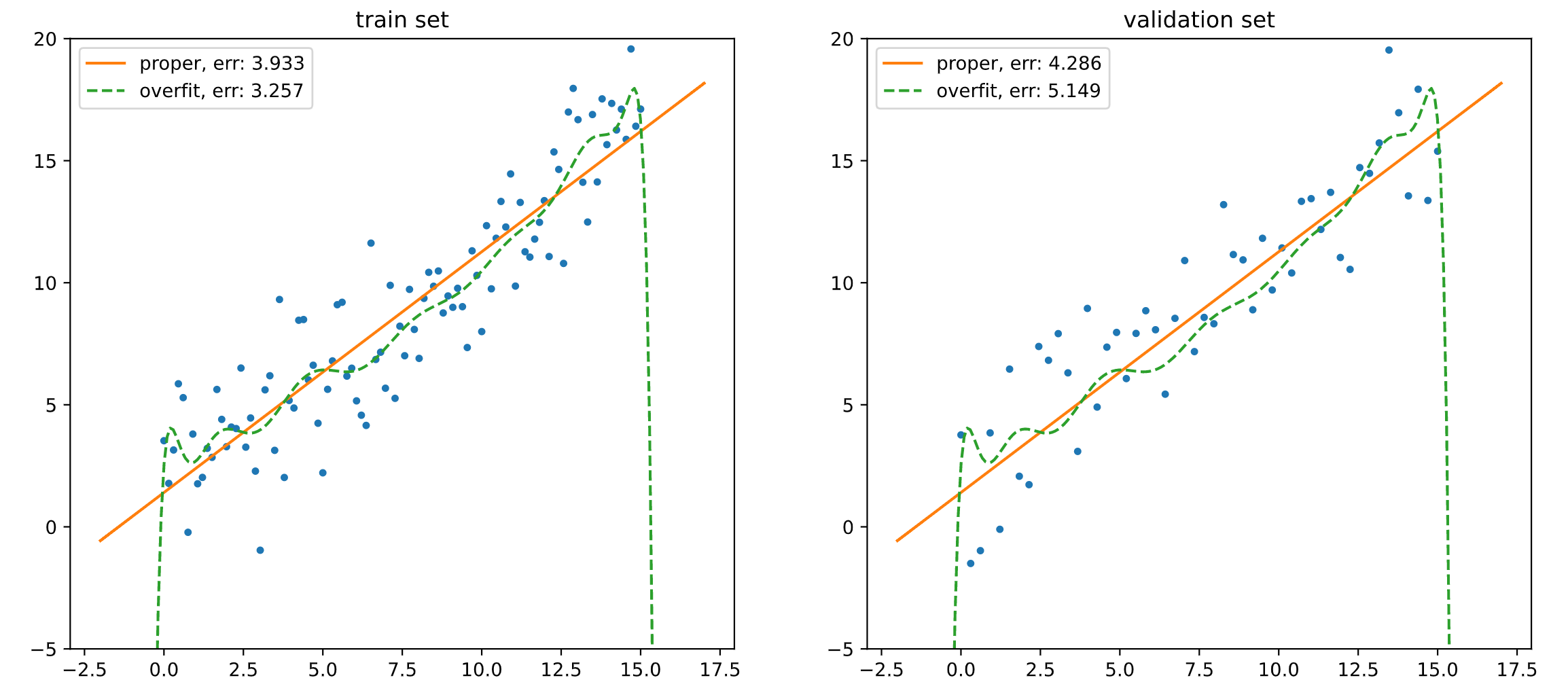
从训练集上的结果来说, 线性模型的误差要明显高于多项式模型. 站在人类观察者的角度来说, 这似乎是显而易见的: 数据是围绕一个近似线性的函数附近抖动的, 那么用简单的线性模型, 自然就无法准确地拟合数据; 但是, 高阶的多项式函数可以进行各种「扭曲」, 以便将训练集的数据拟合得更好.
这种情况下, 我们说线性模型在训练集上欠拟合 (underfitting), 而且它的偏差 (bias) 要高于多项式模型的偏差.
但这并不意味着线性模型在这个问题里要弱于多项式模型. 我们看到, 在验证集上, 线性模型的误差要小于多项式模型的误差. 并且线性模型在训练集合验证集上的误差相对接近, 而多项式模型在两个数据集上的误差差距就很大了.
这种情况下, 我们说多项式模型在训练集上过拟合 (overfitting), 并且它的方差 (variance) 要高于线性模型.
此外, 因为线性模型在两个集合上的误差较为接近, 因此我们说线性模型在训练过程中未见的数据上, 泛化能力更好. 因为, 在真实情况下, 我们都需要使用有限的训练集去拟合模型, 而后工作在无限的真实样本中, 而这些真实样本对于模型的训练过程都是不可见的. 所以, 模型的泛化能力, 是非常重要的指标.
4. How to Balance
在实际应用中, 我们做模型选择的一般方法是:
- 选定一个算法;
- 调整算法的超参数;
- 以某种指标选择最合适的超参数组合;
也就是说, 在整个过程中, 我们固定训练样本, 改变模型的描述能力 (模型复杂度). 不难理解, 随着模型复杂度的增加, 其描述能力也就会增加; 此时, 模型在验证集上的表现, 偏差会倾向于减小, 而方差会倾向于增大. 而在反方向, 随着模型复杂度的降低, 其描述能力也就会降低; 此时, 模型在验证集上的表现, 偏差会倾向于增大, 而方差会倾向于减小.
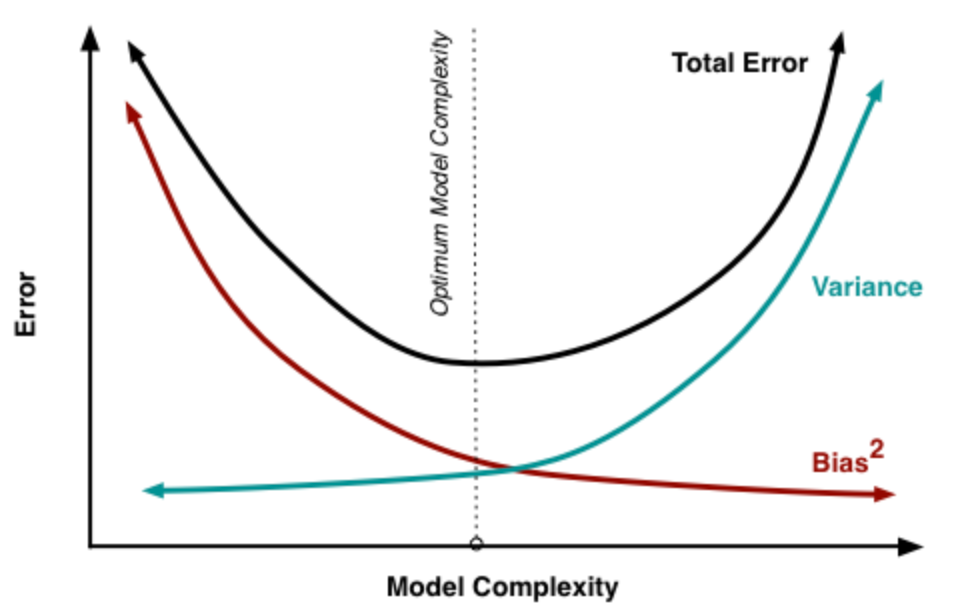
图中的最优位置, 实际上是 total error 曲线的拐点. 我们知道, 连续函数的拐点意味着此处一阶导数的值为 0. 考虑到 total error 是偏差与方差的和, 所以在拐点处, 我们有:
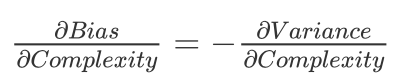
因此, 若模型的复杂度大于平衡点, 则模型的方差会偏高, 模型倾向于过拟合; 若模型复杂度小于平衡点, 则模型的偏差会偏高, 模型倾向于欠拟合.
尽管有了上述数学表述, 但是在现实环境中, 有时候我们很难计算模型的偏差与方差. 因此, 我们需要通过外在表现, 判断模型的拟合状态: 是欠拟合还是过拟合.
同样地, 在有限的训练数据集中, 不断增加模型的复杂度, 意味着模型会尽可能多地降低在训练集上的误差. 因此, 在训练集上, 不断增加模型的复杂度, 训练集上的误差会一直下降. 因此, 我们可以绘制出这样的图像.
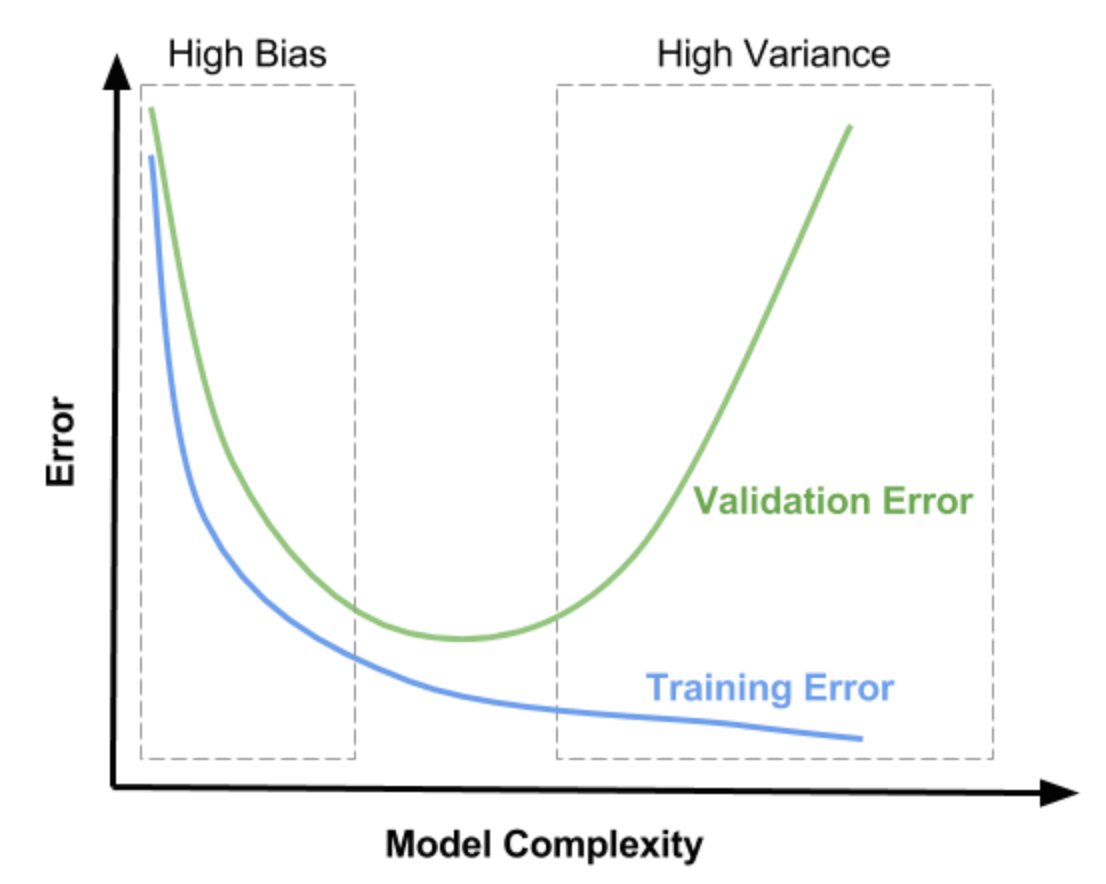
因此:
- 当模型处于欠拟合状态时, 训练集和验证集上的误差都很高;
- 当模型处于过拟合状态时, 训练集上误差很低, 而验证集上的误差非常高.
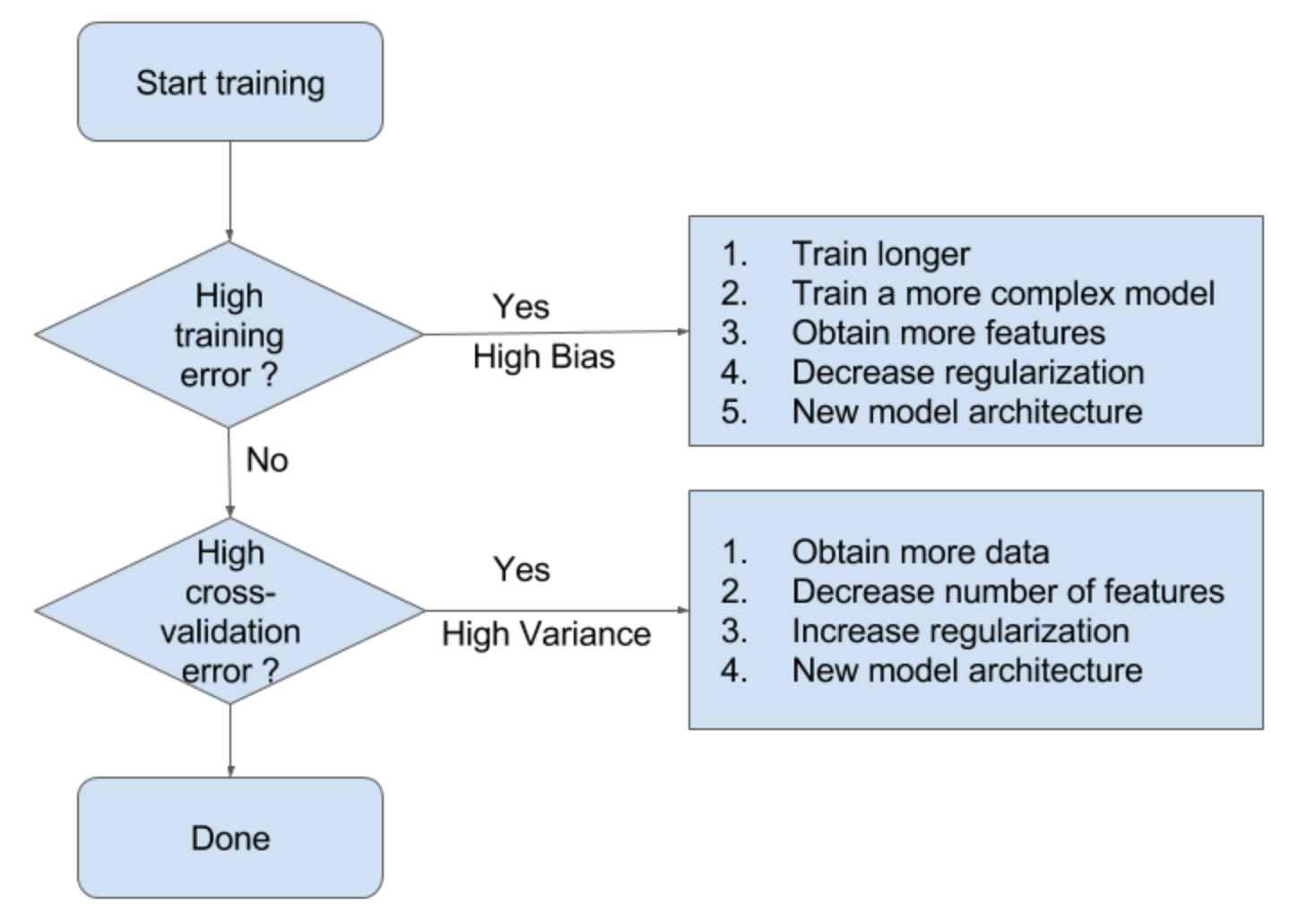
因此, 我们可以开始处理欠拟合和过拟合: